Stories



-
![مونديال 2026]()
مونديال 2026
RT STORIES
"هاتريك" وهدفان في دقيقة واحدة.. شوط أول مثير بين فرنسا والنرويج
!["هاتريك" وهدفان في دقيقة واحدة.. شوط أول مثير بين فرنسا والنرويج]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
قوس قزح أم كأس العالم؟.. إضاءات بفندق منتخب مصر في أمريكا تثير غضبا
![قوس قزح أم كأس العالم؟.. إضاءات بفندق منتخب مصر في أمريكا تثير غضبا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
قبل مواجهة الرأس الأخضر.. سيناريوهات تأهل السعودية لدور الـ32 في كأس العالم
![قبل مواجهة الرأس الأخضر.. سيناريوهات تأهل السعودية لدور الـ32 في كأس العالم]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مع بعض التعديلات.. تشكيل منتخب مصر المتوقع لمباراة إيران في كأس العالم 2026
![مع بعض التعديلات.. تشكيل منتخب مصر المتوقع لمباراة إيران في كأس العالم 2026]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
كأس العالم 2026 تحطم الرقم القياسي لعدد الأهداف في نسخة واحدة
![كأس العالم 2026 تحطم الرقم القياسي لعدد الأهداف في نسخة واحدة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
رد فعل لجنة سياتل على رفض مصر وإيران فعاليات دعم المثليين في كأس العالم
![رد فعل لجنة سياتل على رفض مصر وإيران فعاليات دعم المثليين في كأس العالم]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بعد الخروج من كأس العالم.. رينارد يكشف عن مستقبله مع تونس
![بعد الخروج من كأس العالم.. رينارد يكشف عن مستقبله مع تونس]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مونديال2026.. السنغال والعراق يتواجهان في لقاء الفرصة الأخيرة.. الموعد والقنوات الناقلة
![مونديال2026.. السنغال والعراق يتواجهان في لقاء الفرصة الأخيرة.. الموعد والقنوات الناقلة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مورينيو يفاجئ كريستيانو رونالدو ويختار منافسي البرتغال بالحصول على كأس العالم 2026
![مورينيو يفاجئ كريستيانو رونالدو ويختار منافسي البرتغال بالحصول على كأس العالم 2026]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الموعد والقنوات الناقلة للمباراة الحاسمة بين السعودية والرأس الأخضر في كأس العالم 2026
![الموعد والقنوات الناقلة للمباراة الحاسمة بين السعودية والرأس الأخضر في كأس العالم 2026]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
محمد صلاح يطارد رقما تاريخيا جديدا أمام إيران في كأس العالم 2026
![محمد صلاح يطارد رقما تاريخيا جديدا أمام إيران في كأس العالم 2026]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
حسابات معقدة.. كيف يتأهل منتخب العراق إلى دور الـ32 في كأس العالم 2026؟
![حسابات معقدة.. كيف يتأهل منتخب العراق إلى دور الـ32 في كأس العالم 2026؟]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
رونار يعلق على وداع تونس المونديالي.. ويترك مستقبله مع "نسور قرطاج" غامضا
![رونار يعلق على وداع تونس المونديالي.. ويترك مستقبله مع "نسور قرطاج" غامضا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
وسط أزمة الفعاليات المثلية.. مصر تكشف حقيقة دعوات الانسحاب أمام إيران وحسام حسن يعلق
![وسط أزمة الفعاليات المثلية.. مصر تكشف حقيقة دعوات الانسحاب أمام إيران وحسام حسن يعلق]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
تركيا تودع المونديال بفوز درامي على أمريكا
![تركيا تودع المونديال بفوز درامي على أمريكا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مونديال 2026.. أستراليا إلى دور الـ32 وباراغواي تنتظر
![مونديال 2026.. أستراليا إلى دور الـ32 وباراغواي تنتظر]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
رقم قياسي في مونديال روسيا 2018 بخطر.. وضحيته المنتخبات العربية
![رقم قياسي في مونديال روسيا 2018 بخطر.. وضحيته المنتخبات العربية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
اليابان إلى مواجهة البرازيل.. والسويد تعبر من بوابة "الثوالث"
![اليابان إلى مواجهة البرازيل.. والسويد تعبر من بوابة "الثوالث"]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الأهداف العكسية تلاحق تونس.. وهولندا تحسم الصدارة بثلاثية لتلاقي المغرب
![الأهداف العكسية تلاحق تونس.. وهولندا تحسم الصدارة بثلاثية لتلاقي المغرب]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
نبض اليوم الـ16 يشعل مونديال 2026.. حسابات معقدة وأحلام معلقة
![نبض اليوم الـ16 يشعل مونديال 2026.. حسابات معقدة وأحلام معلقة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![مونديال 2026]() مونديال 2026
مونديال 2026
-
![إسرائيل ولبنان يتوصلان إلى اتفاق إطار]()
إسرائيل ولبنان يتوصلان إلى اتفاق إطار
RT STORIES
سفير إسرائيل في واشنطن: إيران وحزب الله باتا خارج اللعبة
![سفير إسرائيل في واشنطن: إيران وحزب الله باتا خارج اللعبة]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
لبنان.. نائب عن حزب الله ينفي ما نسب إليه حول المفاوضات مع إسرائيل
![لبنان.. نائب عن حزب الله ينفي ما نسب إليه حول المفاوضات مع إسرائيل]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
نتنياهو: الاتفاق الإطار بين إسرائيل ولبنان ضربة كبيرة لإيران (فيديو)
![نتنياهو: الاتفاق الإطار بين إسرائيل ولبنان ضربة كبيرة لإيران (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
قناة عبرية تنشر بنود اتفاق الإطار بين لبنان وإسرائيل
![قناة عبرية تنشر بنود اتفاق الإطار بين لبنان وإسرائيل]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
هيئة البث الإسرائيلية: إسرائيل ولبنان اتفقا على كيفية التعامل مع أنفاق حزب الله ومواجهة تعزيزاته
![هيئة البث الإسرائيلية: إسرائيل ولبنان اتفقا على كيفية التعامل مع أنفاق حزب الله ومواجهة تعزيزاته]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![إسرائيل ولبنان يتوصلان إلى اتفاق إطار]() إسرائيل ولبنان يتوصلان إلى اتفاق إطار
إسرائيل ولبنان يتوصلان إلى اتفاق إطار
-
![فيديوهات]()
فيديوهات
RT STORIES
لبنان وإسرائيل يوقعان "اتفاقا إطاريا ثلاثيا" برعاية أمريكية
![لبنان وإسرائيل يوقعان "اتفاقا إطاريا ثلاثيا" برعاية أمريكية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
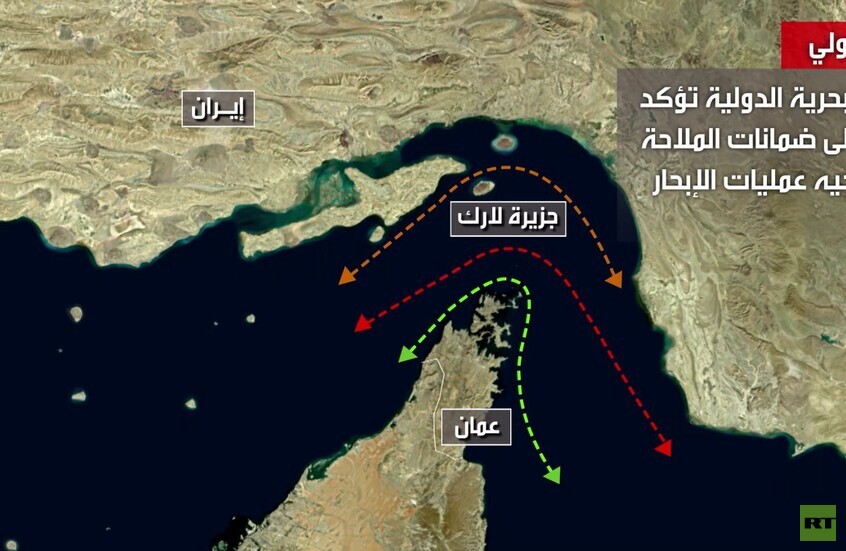
3 مسارات للخروج من هرمز
![3 مسارات للخروج من هرمز]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الصين.. إنقاذ شخصين من سيارة جرفتها سيول مفاجئة في منطقة شينجيانغ
![الصين.. إنقاذ شخصين من سيارة جرفتها سيول مفاجئة في منطقة شينجيانغ]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
تركيا.. اشتعال النار في ملابس زوجين أثناء حفل الزفاف
![تركيا.. اشتعال النار في ملابس زوجين أثناء حفل الزفاف]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![فيديوهات]() فيديوهات
فيديوهات
-
![العملية العسكرية الروسية في أوكرانيا]()
العملية العسكرية الروسية في أوكرانيا
RT STORIES
مقتل شخصين وإصابة أربعة في هجمات أوكرانية على جمهورية لوغانسك الشعبية
![مقتل شخصين وإصابة أربعة في هجمات أوكرانية على جمهورية لوغانسك الشعبية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
المقاتلات الروسية تقصف موقع لواء "نخبة" أوكراني بـ" فاب-1500" (فيديو)
![المقاتلات الروسية تقصف موقع لواء "نخبة" أوكراني بـ" فاب-1500" (فيديو)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
سيناتور روسي يرد على تصريحات ماكرون عن التحول الحاد في موقف واشنطن من الملف الأوكراني
![سيناتور روسي يرد على تصريحات ماكرون عن التحول الحاد في موقف واشنطن من الملف الأوكراني]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
ماسك يدلي بتصريح "خطير" عن دور وكالة أمريكية كبرى في إشعال الحرب في أوكرانيا
![ماسك يدلي بتصريح "خطير" عن دور وكالة أمريكية كبرى في إشعال الحرب في أوكرانيا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
بعد لقاء على الحدود مع نظيرها الأوكراني.. مفوضة حقوق الإنسان الروسية تعلن عن تبادل هام قريب
![بعد لقاء على الحدود مع نظيرها الأوكراني.. مفوضة حقوق الإنسان الروسية تعلن عن تبادل هام قريب]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مقاطعة زابوروجيه.. مدفع هاوتزر الروسي "D-30" يدمر مواقع لقوات كييف
![مقاطعة زابوروجيه.. مدفع هاوتزر الروسي "D-30" يدمر مواقع لقوات كييف]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
روسيا تشيد بالدور التركي وتدعو لاستئناف مفاوضات إسطنبول
![روسيا تشيد بالدور التركي وتدعو لاستئناف مفاوضات إسطنبول]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مقاطعة خاركوف.. منظومة "غراد" تستهدف مواقع تمركز القوات الأوكرانية
![مقاطعة خاركوف.. منظومة "غراد" تستهدف مواقع تمركز القوات الأوكرانية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
لافروف: تصريحات روبيو حول عدم التوصل إلى اتفاق في ألاسكا حول أوكرانيا "تثير التساؤلات"
![لافروف: تصريحات روبيو حول عدم التوصل إلى اتفاق في ألاسكا حول أوكرانيا "تثير التساؤلات"]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجيش الروسي يعلن نتائج الضربة الجماعية السادسة في أسبوع على أوكرانيا
![الجيش الروسي يعلن نتائج الضربة الجماعية السادسة في أسبوع على أوكرانيا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الاتحاد الأوروبي: استبعاد الأوكرانيين في سن التجنيد من الحماية المؤقتة ليس تمييزا
![الاتحاد الأوروبي: استبعاد الأوكرانيين في سن التجنيد من الحماية المؤقتة ليس تمييزا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
حرس الحدود الأوكراني يكذب زيلينسكي: لا وجود لأي استعدادات لغزو بيلاروسي
![حرس الحدود الأوكراني يكذب زيلينسكي: لا وجود لأي استعدادات لغزو بيلاروسي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الجيش الروسي يقصف بقنابل جوية موجهة مراكز تحكم بالمسيرات الأوكرانية
![الجيش الروسي يقصف بقنابل جوية موجهة مراكز تحكم بالمسيرات الأوكرانية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
المفوضية الأوروبية تقترح إلغاء حق اللجوء للأوكرانيين المؤهلين للخدمة العسكرية
![المفوضية الأوروبية تقترح إلغاء حق اللجوء للأوكرانيين المؤهلين للخدمة العسكرية]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
الدفاع الروسية: إسقاط 660 مسيرة أوكرانية غربي البلاد
![الدفاع الروسية: إسقاط 660 مسيرة أوكرانية غربي البلاد]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
أوكرانيا.. قتيل في هجوم على ضباط التجنيد في خاركوف
![أوكرانيا.. قتيل في هجوم على ضباط التجنيد في خاركوف]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
شاهد عيان يروي كيف أضرمت قوات أوكرانية النار في كنيسة بداخلها مدنيون في كونستانتينوفكا
![شاهد عيان يروي كيف أضرمت قوات أوكرانية النار في كنيسة بداخلها مدنيون في كونستانتينوفكا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
ماكرون: الولايات المتحدة لم تعد وسيطا محايدا في أوكرانيا
![ماكرون: الولايات المتحدة لم تعد وسيطا محايدا في أوكرانيا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
موقع أوكراني: سلسلة من الانفجارات تهز كييف مجددا
![موقع أوكراني: سلسلة من الانفجارات تهز كييف مجددا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
ماتفيينكو تقارن استهداف نظام كييف حافلة الأطفال قرب بريانسك بأفعال الفاشيين
![ماتفيينكو تقارن استهداف نظام كييف حافلة الأطفال قرب بريانسك بأفعال الفاشيين]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
القوات الروسية تواصل تقدمها في جمهورية دونيتسك شرق أوكرانيا
![القوات الروسية تواصل تقدمها في جمهورية دونيتسك شرق أوكرانيا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![العملية العسكرية الروسية في أوكرانيا]() العملية العسكرية الروسية في أوكرانيا
العملية العسكرية الروسية في أوكرانيا
-
![اتفاق أمريكي إيراني لوقف الحرب على جميع الجبهات]()
اتفاق أمريكي إيراني لوقف الحرب على جميع الجبهات
RT STORIES
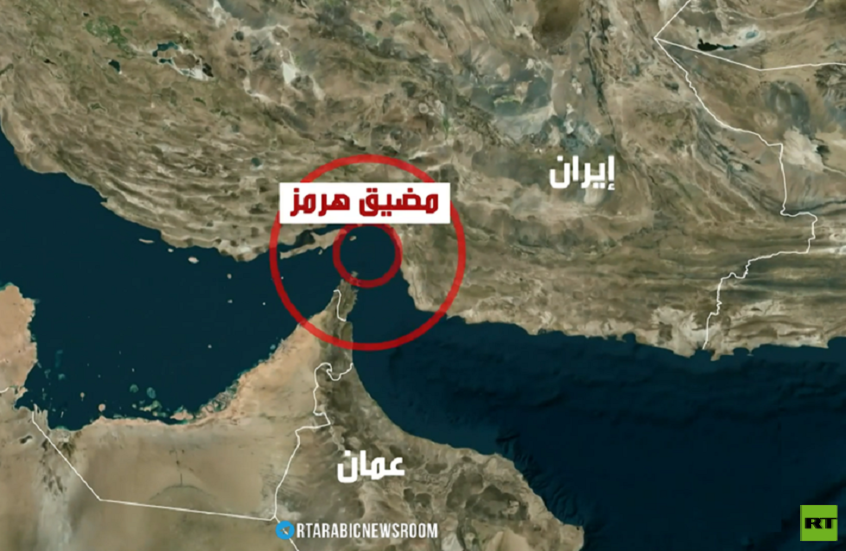
ترامب يتهم إيران بانتهاك وقف إطلاق النار بعد مهاجمتها سفينة "باهظة الثمن" في مضيق هرمز
![ترامب يتهم إيران بانتهاك وقف إطلاق النار بعد مهاجمتها سفينة "باهظة الثمن" في مضيق هرمز]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مسؤول إيراني يحذر دول الخليج من الرهان على السيناريو الأمريكي ويحدد خطا أحمر لا مساومة عليه
![مسؤول إيراني يحذر دول الخليج من الرهان على السيناريو الأمريكي ويحدد خطا أحمر لا مساومة عليه]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![اتفاق أمريكي إيراني لوقف الحرب على جميع الجبهات]() اتفاق أمريكي إيراني لوقف الحرب على جميع الجبهات
اتفاق أمريكي إيراني لوقف الحرب على جميع الجبهات
-
![زلزال فنزويلا]()
زلزال فنزويلا
RT STORIES
زلزال فنزويلا.. سيدة تضع مولودها تحت الأنقاض
![زلزال فنزويلا.. سيدة تضع مولودها تحت الأنقاض]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_MoreRT STORIES
مقتل 235 شخصا وإصابة أكثر من 4300 جراء زلزال فنزويلا وواشنطن ترسل قوات للمساعدة (فيديوهات)
![مقتل 235 شخصا وإصابة أكثر من 4300 جراء زلزال فنزويلا وواشنطن ترسل قوات للمساعدة (فيديوهات)]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More![زلزال فنزويلا]() زلزال فنزويلا
زلزال فنزويلا
-
![الاتحاد الدولي لرفع الأثقال يعيد روسيا للمنافسات تحت علمها ونشيدها]()
الاتحاد الدولي لرفع الأثقال يعيد روسيا للمنافسات تحت علمها ونشيدها
RT STORIES
الاتحاد الدولي لرفع الأثقال يعيد روسيا للمنافسات تحت علمها ونشيدها
![الاتحاد الدولي لرفع الأثقال يعيد روسيا للمنافسات تحت علمها ونشيدها]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More -
![مبابي ضد هالاند.. الموعد والقنوات الناقلة لمواجهة فرنسا والنرويج]()
مبابي ضد هالاند.. الموعد والقنوات الناقلة لمواجهة فرنسا والنرويج
RT STORIES
مبابي ضد هالاند.. الموعد والقنوات الناقلة لمواجهة فرنسا والنرويج
![مبابي ضد هالاند.. الموعد والقنوات الناقلة لمواجهة فرنسا والنرويج]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More -
![المكسيك.. سيارة تدهس مشجعين خلال احتفالات الفوز وتخلف 17 مصابا]()
المكسيك.. سيارة تدهس مشجعين خلال احتفالات الفوز وتخلف 17 مصابا
RT STORIES
المكسيك.. سيارة تدهس مشجعين خلال احتفالات الفوز وتخلف 17 مصابا
![المكسيك.. سيارة تدهس مشجعين خلال احتفالات الفوز وتخلف 17 مصابا]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More -
![بولندا.. صاعقة برق تضرب نافورة في مدينة فروتسواف]()
بولندا.. صاعقة برق تضرب نافورة في مدينة فروتسواف
RT STORIES
بولندا.. صاعقة برق تضرب نافورة في مدينة فروتسواف
![بولندا.. صاعقة برق تضرب نافورة في مدينة فروتسواف]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More -
![الصين.. مياه الأمطار تغمر معظم أنحاء مدينة هوانغشي]()
الصين.. مياه الأمطار تغمر معظم أنحاء مدينة هوانغشي
RT STORIES
الصين.. مياه الأمطار تغمر معظم أنحاء مدينة هوانغشي
![الصين.. مياه الأمطار تغمر معظم أنحاء مدينة هوانغشي]() #اسأل_أكثر #Question_More
#اسأل_أكثر #Question_More
































































البيانات غير المفيدة تجعل الذكاء الاصطناعي "أغبى" وأكثر ميلا للأخطاء!
يحذر الباحثون من أن النماذج اللغوية الكبيرة قد تصبح أقل دقة وأكثر عرضة للأخطاء عندما تُدرَّب على كميات ضخمة من المحتوى منخفض الجودة المنتشر على شبكات التواصل الاجتماعي.

ووفقا لدراسة نُشرت على خادم ما قبل الطباعة arXiv، نقلا عن مجلة Nature، قام علماء من جامعة تكساس في أوستن بتحليل تأثير البيانات "غير المفيدة" — مثل المنشورات القصيرة السطحية ومواد الإثارة — على سلوك الذكاء الاصطناعي. وركّزت الدراسة على جوانب متعددة تشمل المنطق والاستدلال، واستخراج المعلومات من النصوص الطويلة، والأخلاقيات، وحتى السمات الشخصية للنماذج.
وأظهرت النتائج أنه كلما ارتفعت نسبة البيانات الرديئة في عملية التدريب، زادت أخطاء النماذج اللغوية وتراجع منطقها، بما في ذلك في الاختبارات متعددة الخيارات.
وأعاد الباحث الرئيسي تشانغيانغ وانغ التذكير بالمبدأ الكلاسيكي في علوم الذكاء الاصطناعي:"القمامة في المدخلات تعطي قمامة في المخرجات."

أول فنانة ذكاء اصطناعي توقع عقدا بملايين الدولارات.. من هي
وأكد التحليل الجديد أهمية انتقاء البيانات بعناية عند تدريب النماذج. فقد استخدم الباحثون مليون منشور من منصة تواصل اجتماعي شهيرة لإعادة تدريب النموذجين المفتوحين Llama 3 وQwen — حيث يُعرف الأول باتباع التعليمات، بينما يُصنف الثاني كنموذج استدلالي.
وأظهر التحليل أن نموذج Llama تغيّر سلوكه بعد التدريب على البيانات منخفضة الجودة، إذ انخفضت السمات "الإيجابية" وظهرت سمات "سلبية" مثل النرجسية والاعتلال النفسي.
أما محاولات تصحيح الخلل — مثل إعادة التدريب على بيانات عالية الجودة أو تعديل التعليمات — فقد حسّنت الأداء جزئيًا فقط، بينما استمرت مشكلات التفكير المنطقي وتخطي الخطوات التحليلية.
ويكتسب هذا الموضوع أهمية خاصة في ظل توجه منصات التواصل الاجتماعي إلى توسيع استخدام بيانات المستخدمين لتدريب أنظمة الذكاء الاصطناعي. فعلى سبيل المثال، تخطط شركة LinkedIn اعتبارا من نوفمبر الجاري لاستخدام بيانات المستخدمين الأوروبيين في أنظمتها التوليدية.
المصدر: Naukatv.ru
إقرأ المزيد

موظفو ماسك يجبرون على التنازل عن "وجوههم وأصواتهم" من أجل الروبوت "آني المثيرة"
في خطوة تثير تساؤلات أخلاقية وقانونية عميقة، كشف تقرير حديث أن موظفي شركة إيلون ماسك للذكاء الاصطناعي xAI اضطروا لبيع بياناتهم الشخصية للمساعدة في خلق روبوتات دردشة "مثيرة".

خطة طموحة من إيلون ماسك لـ"تعتيم الشمس" تثير جدلا واسعا
كشف إيلون ماسك عن خطط طموحة لمواجهة الاحتباس الحراري عبر إطلاق مجموعة ضخمة من الأقمار الصناعية المزودة بالذكاء الاصطناعي، بهدف تعديل كمية الإشعاع الشمسي التي تصل إلى الأرض.
































































































التعليقات